[미국] 마키나락스(MakinaRocks, Inc.), 제조업 생산성 향상을 위한 AI 솔루션
어떤 중장비가 망가질지 예측하는 것이 바로 산업용 AI
2024-04-11 오후 12:33:57


□ 연수내용
◇ 제조업에 특화된 AI서비스와 솔루션 제공이 목표
○ 마키나락스는 2017년 12월 설립된 제조업에 특화된 AI서비스와 솔루션을 제공하는 스타트업으로 생산공정에 AI를 도입해 기계 고장이나 품질 이상 등을 예측하는 제조업에 특화된 AI서비스와 솔루션을 제공한다.
○ 마키나락스는 Makina는 라틴어로 machine이다. Machine Intelligence를 폭넓게 해석한 것이다. Rocks는 Shaking으로 '인공지능을 통해 산업을 뒤흔들다'라는 뜻을 가졌다.
 ▲ 이재혁 대표[출처=브레인파크] |
○ 기계 인텔리전스, AI의 실행(Operation)을 통해 제조업을 다시 정의, 산업을 좀 더 효율적으로 만들자는 비전을 가지고 산업용 AI 솔루션과 제조업과 에너지 산업의 성장을 도모하는 플랫폼을 개발하는 것이 목표이다.
◇ SK텔레콤에서 AI관련 팀이 분사하여 창업
○ SK텔레콤에서 ‘제조업 특화 AI 데이터 분석 솔루션 기술’을 개발했던 SK텔레콤 소속 관계사(화학회사, 유공 등)에 Digital Transformation(디지털 변환)팀, 특히 인공지능 관련 데이터 분석하는 팀이 분사하여 1대 주주, 2대 주주는 SK텔레콤이다. 실리콘밸리와 서울 오피스에서 17명이 일하고 있다.
○ 회사에 이해를 구한 상태에서 2017년 12월 한국에서 회사를 창업하고 2018년 미국 지사를 만들었다. SK텔레콤에서 3명, 삼성전자에서 1명 영입해서 4명으로 회사를 시작했다. 2018년 5월 SK텔레콤, 네이버, 현대에서 Seed-round 펀딩을 받았다.
○ 이때 Seed-round란 처음에 회사를 만들면 시드(씨앗) 단계라고 한다. 그 다음으로 a, b, c, d 단계가 있다. 시드는 회사를 만들 때 자금이 필요한 단계, a는 뭔가를 발견해서 투자자들을 설득하는 단계, b는 발견한 것들 중 특정 무언가를 밀고 나가서 더 확장시키는 단계, c는 지역적으로 더 확장하거나 사람도 더 뽑고 매출도 올리는 단계(IPO, Initial Public Offering)이다. 보통 c가 터닝 포인트가 된다.
○ 시드 단계에서는 보통 개인 투자를 받거나 창립자들이 돈을 내는데 마키나락스는 SK텔레콤이 자금을 지원했기 때문에 매출이 발생하면서 회사를 시작할 수 있었다.
SK텔레콤, 네이버, 현대에서 20억 정도의 투자를 받았다. SK텔레콤이 외부 투자자 중에서는 지분을 가장 많이 받고 있다. B2B 하는 분들은 회사에 있거나 아이템을 발견해서 분사하는 경우가 많다.
◇ SK텔레콤이 운영하는 스타트업 인큐베이션 공간에 입주
○ 한국에서 창업 후 실리콘밸리에 자회사를 설립해 글로벌 하이테크 반도체 기업을 파트너로 확보했으며, 한국과 미국에서 반도체나 자동차 생산라인, 미생물 공정 생산라인 등에서 프로젝트를 진행하고 있다.
○ 실리콘밸리 자회사는 SK텔레콤이 운영하는 스타트업 인큐베이션 공간, Inno- partners에 있다. 인큐베이션 공간과 경쟁적인 형태로 나온 것이 공유 오피스로 WeWork, 스타플레이스 등이 유명하다. 공유 오피스와 인큐베이션 공간의 차이는 공유 오피스는 임대료가 있고 인큐베이션 공간은 임대료가 없다는 것이다.

▲ Innopartners 입주기업들
○ Innopartners는 실리콘밸리 센터에 위치하고 있는데 스탠포드 대학교가 있고 그 앞에 멘로파크가 있다. 멘로파크에서 반도체 사업이 제일 먼저 시작했다.
반도체 사업은 공해가 극심하다. 중간에 메인 공정 중 방사선 쏘는 방식은 공해가 별로 없는데, 독한 화학 물질로 깎아내리는 방식과 산업용 가스로 위에 쓰이는 방식(deposition)은 공해가 많이 발생해서 한국과 대만에서 공정을 진행하고 실리콘밸리에서는 설계, R&D하는 반도체만 남아 있다. 그 뒤로 소프트웨어, 하드웨어 사업이 주로 발달하게 되었다.
◇ 어떤 중장비가 망가질지 예측하는 것이 바로 산업용 AI
○ 산업용 AI가 나올 수 있던 배경은 IoT, 빅 데이터, AI이다. 각 분야별로 데이터 분석은 조금씩 다르다. IoT 시절 데이터 분석은 On&Off였다. 건설 중장비가 켜져 있는지, 꺼져 있는지만 잘 알아도 가능했다.
Uptake가 이 때 나온 회사이다. On&Off를 잘 측정하고 왜 잘 안됐는지 데이터를 분석하고 축적하면서 등장한 것이 빅 데이터이다. 빅 데이터는 왜 작동이 잘 되지 않았는지 이유를 찾는 데 분석이 특화되어 있다. 어떤 중장비가 망가질 것인지 예측하는 것이 AI이다.
○ 마키나락스가 하고 있는 것은 제조업의 다양한 문제를 AI기술을 접목해서 해결하려고 하는 것이다. 예를 들어 반도체의 경우 장비 하나가 비싼 것은 4000억 정도이다.
따라서 망가지면 안되는데 1년 365일 24시간 작동시키고 독한 화학물질과 가스를 쓰기 때문에 망가질 수밖에 없다. 가동률을 낮추는 원인이 되는 이런 비싼 장비가 언제 망가질지 예측해서 가동률을 올리는 것이다. 해마다 다르지만 1%의 수율만 올라가면 이익이 1조 올라간다.
○ 또 다른 예는 화학 공정에 가보면 파이프라인이 길게 연결되어 있는데, 파이프라인의 특정 부분이 막히기 마련이다. 막히는 걸 미리 예측하면 공정 가동률과 수익이 올라간다.
그래서 산업용 AI 솔루션은 기존 가정에서 사용하는 AI 제품보다 높은 수준의 예측력을 보유한 AI를 필요로 한다. 기존 AI가 알고리즘과 데이터가 성능을 좌우한다면 마키나락스가 개발한 솔루션은 알고리즘, 데이터에 도메인 지식이 더해져 예측력면에서 뛰어나다.
○ 마키나락스는 딥러닝 기반의 PdM(Predictive Maintenance) 알고리즘 및 관리 기법을 적용해, 제조 장비 및 공정에서 발생하는 센서 데이터를 분석을 토대로 △장비 고장 및 품질 이상 예측 △제조 불량 분석 △공정 최적화 솔루션을 제공해 공장의 생산성 및 품질 향상에 기여하고 있다.
○ 마키나락스가 자체개발한 인공지능 솔루션은 최소 100억 원대부터인 반도체나 자동차 생산 설비의 고장이나 오류를 짧게는 12시간, 길게는 5일 전에 예측할 수 있도록 설계돼 막대한 손실을 예방한다.
◇ 좋은 데이터와 데이터 기술자 확보를 위한 실리콘밸리 진출
○ 한국에서 기업 솔루션을 제공하는 기업들이 많이 실패했다. 가장 큰 이유는 데이터가 있어야 하는데, 데이터 자체가 굉장히 흠이 있는 데이터라는 점이다. 장비가 얼마나 망가졌는지 외부에 알려줘야 하기 때문에 어려운 부분이다.
○ 또한 데이터를 분석할 수 있는 기술자들의 인건비가 굉장히 높고 인력이 귀하다. 최소 연봉이 3억이다. SK텔레콤에서 인건비를 들여서 기술자들을 한국으로 데려와도 기술자들이 한국에서 일하고 싶어하지 않는다.
한국에 가더라도 데이터 분석하는 부지는 다 지역에 있어 지역에 가려고 하지 않기 때문이다. 따라서 대기업도 기술자들을 확보・유지하기가 어렵다.
그래서 최근 실리콘밸리에 SK Hynix가 진출하여 데이터 분석 기술자가 Hynix가 있는 이천으로 가지 않고 실리콘밸리에서 새로 지은 건물에서 데이터 분석을 할 수 있도록 하는 것이다.
◇ 적용이 쉽지 않았던 산업용 AI
○ 산업용 AI라는 개념은 예전부터 등장했지만 잘 적용되지 않았다. 포스코가 IoT 시절부터 투자를 많이 했었고 투자를 오랫동안 해서 데이터 분석을 열심히 했지만 지역에 위치하고 있어서 기술자들을 오랫동안 확보하지 못했다. 포스코는 빅 데이터에서 AI 분석까지 5년동안 프로그램을 실행했고 아래 2개를 많이 공표한다.
• 용광로, 고로 온도를 일정하게 만드는 알고리즘: 변수가 많아서 어려운 부문이다.
• 아이언 도금 최적화 공정
‘○ 데이터 시티즌십’이라고 하는 어느 정도 역량이 있으면 교육을 받고 데이터 기술자가 될 수 있는 프로그램이 있다. 이런 프로그램을 통해 일상생활의 간단한 문제를 해결할 수 있다.
SK텔레콤도 데이터 시티즌십을 통해 어떤 신입사원이 먼저 퇴사할 것인지에 대한 알고리즘을 만들었다. 그러나 정작 중요한 수율이 올라가는 과정에 대해서는 잘 없다.
예전에는 노하우가 많은 엔지니어가 변수 여러 개를 두고 수율을 계산했으나 빅 데이터를 통해 변수가 늘어나면서 AI가 등장하게 된 것이다.

▲ 산업용 AI 접목을 위한 4개 요소[출처=브레인파크]
◇ 산업용 AI 접목
○ 산업용 AI의 접목을 위해서는 아래 4개 요소가 필요하다.
• 연결성 : 반도체의 경우 2014년 Hynix 인수할 때 공정 수가 300개였는데 2018년 기준 600개가 됐다. 내년 새로운 Fab이 만들어지면 800개가 넘어갈 것이다.
• 복잡성 : 간단한 문제는 AI를 사용할 필요가 없고 빅 데이터, SAS 툴을 사용하면 된다. 하지만 문제가 점점 복잡해지기 때문에 AI를 사용해야 한다.
• 기술 : 딥 러닝 아키텍처(컴퓨터 시스템의 구성)에서의 매개변수
• 투자 : CAGR(연평균 성장률) 170억 + 2025 시장 (제조업에서의 산업용 AI) Þ 40% 상승
◇ 소비자 중심 AI와 산업용 AI의 차이점
○ 소비자 지향 AI와 산업용 AI의 차이는 사람이 잘하는 분야에 대해서도 사람보다 기계가 일을 많이 하는 것이 소비자 AI라면, 산업용 AI의 목적은 장비가 너무 복잡해서 언제 망가질지 사람이 예측할 수 없는 그런 부분을 예측하는 것이다.
|
소비자 중심 AI |
산업용 AI |
|
|
목표 |
자연 지능과 관련된 업무에 초점 |
산업 문제와 관련된 업무에 초점 (예를 들어 수율 향상, 인간의 지능으로 해결하기 힘든 최적화) |
|
적용 |
언어 번역, 자율 주행, 비디오 감시 |
PDM(예측정비), 결함 추정, 공정 최적화 |
|
데이터 |
인간이 해석 가능한 데이터(사진, 비디오, 텍스트, 음성, 소비자 프로필과 활동 등) |
인간이 해석할 수 없는 데이터(센서 값, 처리 이미지, 현지 기술자 업무 등) |
○ 사람이 공정 수가 너무 많으면 최적화할 수 없기 때문에 AI가 한다. 사람이 도입한 것이기 때문에 사람 일자리를 위협하는 것을 제외하고 AI로 대체하는 것이다.
B2C는 사람들이 다 이해하는 데이터(사진, 텍스트, 비디오 등), 후자는 사람이 이해하기 어려운 데이터(센서 데이터 그래프, 프로세스 이미지 등)이다. 프로세스 이미지는 예를 들어 자동차 부품 안을 찍어서 보면 실금이 잘 보이지 않기 때문에 AI가 찾아내는 것이 필요하다.
◇ 산업계에서 산업용 AI의 문제점
○ 투자자들이 인공지능에 많은 투자를 하고 있고 산업용 AI에 대해서만 2025년까지 17조 원의 시장으로 확대될 것으로 보고 있다. 마키나락스와 같은 기업이 필요한 이유는 사람들이 시작은 많이 하지만 70% 정도가 잘 되지 않기 때문이다.
산업용 AI를 적용하기 위한 4단계가 있다.
• 첫째, 개념 검증(PoC, Proof of Concept)
• 둘째, 파일럿(실전 테스트 라인 선정)
• 셋째, 생산 라인 적용(Deployment)
• 넷째, 확장(한 두개 생산에서 공장 전체로 확장 )
○ 하지만 대부분 2단계 파일럿에서 끝난다. 이유는 센서 데이터를 해석할 정도가 되려면 전문가이거나 데이터 처리를 사전에 많이 해본 사람이어야 하는데, 그런 경우가 많이 없기 때문이다.
◇ 산업용 AI가 해결해나가야 할 도전과제
○ 앞으로 해결해나가야 할 도전과제는 다음과 같다. 첫째, 늘어나는 복잡성, 더 높은 기대, 적용 과정에서의 고위험 등에 대한 ‘문제 정의(Problem Definition)’가 필요하다.
실제 현장에서 발생되는 문제는 프로젝트 정의가 먼저 이루어져야 하는데, 시장 자체가 초기 적응 단계이다. 이 단계에서는 어떤 문제를 AI 기술로 해결할 수 있는지 아는 것이 어렵다.
각 대기업마다 자랑하는 기술이 딱히 없다. 삼성에서 자랑하는 것은 AI 기반 빅데이터 플랫폼인 Brightics인데, 아직까지 이 플랫폼을 가지고 뚜렷하게 개선한 사례는 아직 없다.
○ 둘째, 불균형 또는 잡음 라벨, AI 역량 부족, 도메인 지식 통합에 대한 알고리즘(Development)이 필요하다. 문제를 풀려면 도메인 지식이 있어야 하는데 30대 초반의 유능한 필드 엔지니어를 서울대에 6개월 데이터 분석 과정에 보내서 가르치면 데이터 분석 기술자가 되는지 실험해봤으나 데이터 분석 기술자가 되는 것이 아니라 수학만 배우고 온다는 결과가 나왔다. 배경지식이 많고 경험 있는 기술자를 찾는 것이 어렵다.
○ 셋째, 시스템 통합, 연속적인 학습, 모델 관리를 통한 작동(Deployment)이 필요하다. 노조원이나 현지 엔지니어는 자신들의 일자리를 없앤다고 생각해서 기계 시각(Machine Vision Project)을 선호하지 않는다.
따라서 PoC, 파일럿은 잘 되는데 Deployment가 어렵다. Machine Vision 구현 사이트를 1년 후에 들어가면 방치되어 있는 것들이 많다. 한국에 기계 시각을 구축할 수 있다는 SI(System Integrator, 시스템 통합 사업자) 업체가 협회에 등록된 것만 400개가 넘는다.
그러나 정작 성공사례는 없다. 현재 기술의 현주소이다. 시작하더라도 3단계 Deployment할 때 현실적인 문제는 정상 데이터, 비정상 데이터이다.
1만 장씩 각각 있다는 공장은 현실에 없다. 흔한 예로 그냥 정상 데이터가 1만 장, 비정상 데이터는 두 장밖에 없다. 정상 데이터는 많고 비정상 데이터는 없다.
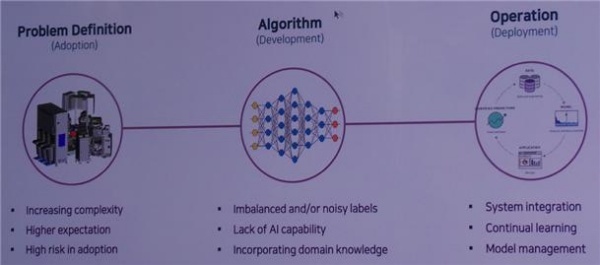
▲ 산업용 AI가 해결해나가야 할 도전과제[출처=브레인파크]
◇ 산업용 AI에 초점을 맞춘 기계 학습
○ 크게 4가지 정도의 핵심 기술이 있다. 최근에 딥러닝 모델을 활용한 스타트업 기업들이 많아지고 있다. 딥러닝 모델에 기반하여 주어진 데이터를 가지고 어떻게 좋은 학습 모델을 만들지 집중하는 경우가 많은데 이 분야에서 일을 하다 보니 이 부분도 중요한 것은 맞지만 그 외에도 성공하기 위해 다른 기술들이 많이 필요하다는 것을 알았다.
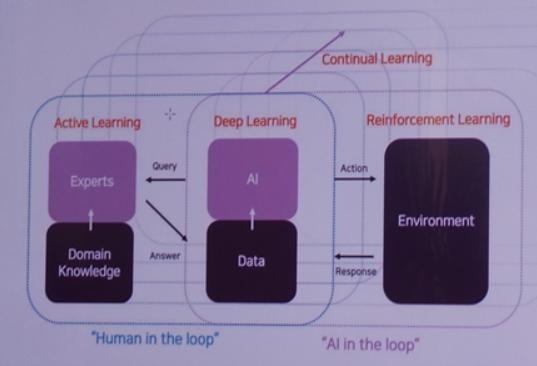
▲ 마키나락스의 4개 핵심 기술[출처=브레인파크]
○ 첫째, Active Learning이다. 데이터를 전부 라벨링할 수 없고 레이블은 얻으면 얻을수록 도움이 되기 때문에 효율적으로 얻어야 한다.
샘플링을 한 번 할 때마다 비용이 들기 때문에 비용을 최소화하면서 모델의 성능을 올릴 수 있는 라벨링은 무엇인지 찾는 것이 중요하다.
어떤 데이터 샘플을 뽑아야 라벨링이 효과적일지, 뽑은 데이터 샘플을 어떤 방식으로 엔지니어 혹은 도메인 전문가들에게 요청해야 흔쾌히 수락할지 2가지 측면에서 고민하고 있다.
연속적으로 클릭해서 라벨링 해야 하면 불편해서 수락하지 않을 것이고, 드롭 다운 메뉴에서 고르거나 한 번 클릭할 수 있는 샘플이면 수락할 것이다.
○ 둘째, Deep Learning이다. 일반적인 이미지, 텍스트 데이터 라벨링은 비용이 들어도 모든 사람이 할 수 있어서 클라우드 소싱 방식을 선택할 수 있고 데이터가 공개되어 있는 경우가 많아서 작업이 수월하다. 반면 산업용 데이터는 굉장히 제한적인 사람들만 접근이 가능하고 소수만 고장이 났는지 체크할 수 있다.
○ 셋째, Continual Learning이다. 아카데미에서는 새로운 과제를 학습할 때 과거에 학습했던 과정도 잊지 않고 잘 가지고 있는 것을 말한다.
반면 산업에서는 하나의 장비를 사용하더라도 제조 환경은 계속 바뀌는데, 달라질 때마다 계속 새로운 모델을 만들 수 없기 때문에 계속 변화하는 환경에서 모델 성능을 사람의 개입 없이 어떻게 잘 유지할 수 있을지 고민하고 있다.
○ 넷째, Reinforcement Learning이다. 마키나락스도 Reinforcement Learning을 중심으로 하는 프로젝트가 있기는 하지만 보통 시뮬레이션이 가능한 환경이다.
반도체, 자동차 장비처럼 좋은 시뮬레이터가 없는 경우 마키나락스가 사용하는 데 아직까지는 제한이 있다. 데이터를 마음대로 뽑을 수 없기 때문에 쓸 수 있는 부분에서만 최대한 활용하려고 한다.
◇ 우리가 가지고 있는 기술: 어플리케이션의 핵심
○ 핵심 기술로부터 발견한 주요 어플리케이션으로 자동화, 주요 원인 찾기 등이 있다. 이런 분야에 대해서 내부적으로 연구, 개발하고 있고 프로젝트를 하면서 얻은 기술을 IP로 쌓아가고 있다. 경우에 따라서 어떤 기술은 논문으로도 가치가 있다고 느껴지면 논문도 제출하고 있다.
○ 가장 첫 단계로 기계 데이터 분석(Machine Data Analytics)이 이루어진다.
• 센서 & 시계열데이터 분석 기술
○ 다음 단계에서 △비정상 행위 탐지(Anomaly Detection), △시간 예측(Event Forecasting), △근본 원인 분석(Root Cause Analysis), △공정 최적화(Process Optimization)가 이루어진다.
• 패널 이미지에서의 결함 추정
• SVD 분해를 이용한 태양열 예측
• 바이오리액터(생물 반응 장치) 자율제어
• NNM(Neural Network Model, 신경망 모형)을 이용하여 다양한 제조 장비 환경에서 이상징후감지
• 딥 러닝 모델에 기반하여 자산 고장 예측하기 위해 준 감독 학습
○ 마지막으로 4개 핵심기술 △Active Learning, △Deep Learning, △Continual Learning, △Reinforcement Learning이 활용된다.
• Continual Learning을 사용한 이상징후 감지
• Layerwise Information: loss-based 이상치 탐지
• 산업 데이터에 대한 딥 러닝 분석
• Class-labeled 이상치 탐지
• 딥 러닝 모델을 이용한 데이터 라벨링
○ 프로젝트를 할 때 필요한 모델을 구현하거나 누군가가 구현해 놓은 코드를 활용하는 경우가 있는데, 두 경우 다 검증이 안된 것이라는 문제점이 있다.
따라서 마키나락스는 자체적으로 자주 쓰이는 모델을 구현하고 검증도 마쳐서 필요할 때 신속하게 활용할 수 있게 한다. 또한 구현해 놓은 모델에 새로운 구성요소를 붙여서 융통성 있게 활용할 수 있도록 한다.
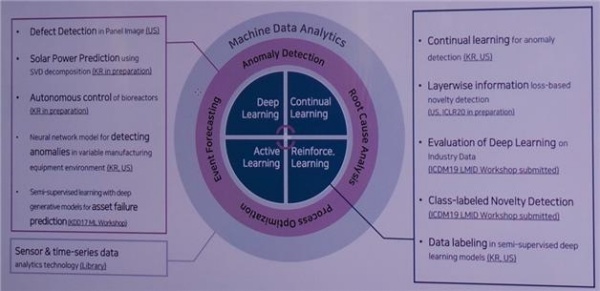
▲ Core to Applications[출처=브레인파크]
◇ 다양한 부문에 적용되는 산업용 AI
○ 일반적인 제조업이 아니라 반도체, 배터리 등 수백 가지 공정까지 가는 여러 가지 변수를 가진 제조 과정이 관련되어 있는 산업을 High Complexity 산업이라고 한다. 딥러닝 기술이 유의미하다고 보는 4가지 산업분야는 다음과 같다.
• 반도체 & 디스플레이(Semiconductor & Display): 장비예측정비(PdM), 가상계측(VM), HVAC(Heating, Ventilation, Air Conditioning: 공기조화기술) 최적화
• 화학, 제약(Chemicals & Pharma): 프로세스 자동조종장치, 품질검사, 장비예측정비(PdM)
• 자동차, 자동차 부품(Automotive): 로봇예측정비(PdM), 조직상 결함 감지, HVAC 최적화
• 파워 & 에너지(Power & Energy): 태양열 & 풍력 예측, 배터리 응용프로그램, 발전 최적화
◇ 최소 12시간 전 고장을 예측하는 Semicon Time-To-Failure
○ 이러한 기술들이 실제로 공장, 산업에 쓰이고 있는 주요 프로젝트를 소개하면 다음과 같다.
○ Semicon Time-To-Failure라는 프로젝트를 통해 반도체 세계 1위 장비 기업과 일하고 있다. 유명한 하이테크 기업의 시초가 실리콘밸리에 있어서 부지값이 매우 비싸고 수십억에서 수천억에 달하는 반도체 장비를 활용하는 기업이 많다.
이들 기업은 부품이 망가지기 전에 교체, 공정을 바꿔주는 등 일을 해야 하는데 엔지니어들이 항상 24시간 대기하고 있을 수 없기 때문에 미리 예측할 필요성이 점점 커지게 되어 프로젝트가 시작되었다.
프로젝트 시작시 다른 여러 경쟁사에 똑같은 데이터 원본을 주고 모델을 만들어보라고 했는데 결과적으로 마키나락스가 1등을 했다. 경쟁 업체 중에선 IBM USA, 실리콘밸리 스타트업 등이 있었다.
○ 2년 이상 프로젝트를 진행해왔고, 3단계까지 왔다. Validation Pilot을 하고 있고 내년에는 추가적으로 더 구체적인 Development 프로젝트를 할 것이다.
○ 최소 12-24시간 전에 고장을 예측・감지할 수 있고 30-50% 다운타임(정지시간)을 줄일 수 있다. 정확도는 90%이다. 이는 2년치 데이터(정상적인 이벤트, 실패한 이벤트 등) 중 90%를 정확하게 맞췄음을 뜻한다.
○ 반도체 센서 종류가 보통 200-400개, 평균 300개가 있는데 300개 센서 데이터 값을 계속 받아보는 것은 실제 온라인 데이터로 하고 있다. 프로젝트의 고도화가 이렇게 진행되고 있다.
◇ 완성차 제조현장의 로봇고장 예측 프로젝트
○ Robot Arm Anomaly Detection 프로젝트도 고장을 예측하는 프로젝트인데, 완전히 다른 산업인 완성된 차를 제조하는 공장에서 쓰이고 있는 산업용 로봇의 고장을 예측한다.
매번 다른 산업을 접할 때마다 도메인 지식과 여러 기술이 필요한데, 이 경우 Semi-supervised Novelty Detection 기술을 가지고 동일한 컨셉을 로봇 팔에 적용했다.
○ 로봇 팔은 평균 1억 2천만원 정도이며 그 자체로는 고가의 장비가 아니다. 그래서 창고에 부품을 쌓아놓고 고장이 나면 정비사가 갈아끼우는데 30~40분도 걸리지 않는다.
문제는 외국은 1분당 차가 한 대씩 완성되기 때문에 자동차 라인에서 로봇이 수십대에서 수백 대가 늘어져 있고 다운타임이 30분 이상 생기면 어마어마한 손실이 발생한다는 점이다. 따라서 고객사에서 사용하고 있는 로봇의 고장을 최소 3~5일 전에 알았으면 좋겠다는 요구가 있었다.
○ 작년까지 쓰인 산업용 로봇이 260만대가 있고 매년 15%씩 증가할 것이라는 산업연구결과가 나오고 있다.
○ 반도체가 300가지의 여러가지 다른 데이터 값을 사용했다면 로봇 팔은 순간전류값만 가지고 모델을 만들 수 있었다. 순간전류값은 그 축에 있는 센서에서 나오는 로봇의 표준값인데 Kawasaki, Denso, Honda, ABB, 유니버설 회사에서 순간전류값으로 토크(Torque)를 계산한다.
○ 일본 로봇 제작사와 인터뷰도 하고 벤치마킹도 시도해봤는데 그들이 쓰는 룰에 따라 필요한 센서 값, 실험을 통해서 그리스에서 나오는 철 농도를 계산한 값을 사용하고 있었다.
앞으로 방향은 PdM 솔루션이고 예지가 아니라 예방에 집중한다고 한다. 추가적인 센서, 바이브레이션을 메이커 회사의 부품 뿐만 아니라 타사에서도 유사한 데이터를 뽑아낼 수 있을지를 고민하고 있다.
○ 정확도는 90%이며 5일전에 고장을 감지할 수 있다. AI 솔루션(Edge와 클라우드 관련)을 활용하며 몇백만 달러를 절감하는 효과를 낸다.
◇ 초기 단계의 결함을 검출, 큰 손실을 예방하는 프로젝트
○ Auto Body Defect Detection프로젝트는 프레스 기계로 자동차 부품 중에 하나인 보닛, 루프를 만드는 제조현장에서 자주 겪는 이슈인 금속판에 스크래치가 생겨날 때 CNN 기술을 사용해서 외관 검사하는 프로젝트이다.
○ 결함이 있는 부품을 계속 조립한다해도 마지막 단계인 품질단계에서 제품으로 출시될 수 없기 때문에 처음 단계로 다시 되돌아가야 한다.
당시에는 제조현장에서 엔지니어들이 육안으로 확인해야 했는데 마키나락스의 모델을 활용함으로써 앞으로는 전수 확인이 가능하다. 초기 단계에 결함을 빨리 검출해서 향후에 있을 큰 손실을 미리 예방하자는 취지에서 진행했다. 정확도는 95%에 달한다.
◇ 계량 데이터에 기반한 공정 최적화 프로젝트
○ 미생물 공정 자동조종장치(Microbial Process Autopilot) 프로젝트는 제약사에서 미생물을 직접 키워서 거기서 나오는 바이오 물질을 제약을 생산하는 데 쓰는데 미생물의 생산을 담당하는 주요 장비가 바이오리액터이다.
미생물이 잘 자라서 필요한 바이오 물질이 나오도록 사람이 parameter setting을 계속 하면서 최적의 조건을 맞춰줘야 하는데 지난 과거의 데이터를 기반으로 최적의 모델을 만들어서 자동으로 조정할 수 있게 해달라고 고객이 요청해서 POC도 성공적으로 맞추고 모델을 만들었다.
올해 연말에 2단계를 진행할 예정이다. 제약사 뿐만 아니라 바이오리액터를 사용하는 곳이면 다 적용할 수 있다고 보고있다.
○ 리튬 배터리 결함 예측(Li+Battery Defect Prediction) 프로젝트는 리튬 배터리 셀메이커와 진행했던 프로젝트. 배터리 수율을 높이기 위해 제조공정에서 공정인자 중 어떤 것이 결함에 영향을 주는지 결함에 대한 분석을 요청해왔다. POC는 끝나고 추후 2단계를 진행할 것이다. 정확도는 90%이며 정렬되지 않은 데이터 원본으로부터 결함 요인을 분석할 수 있다.
○ 태양열 발전량 예측(Solar Power Prediction) 프로젝트는 커머셜 프로젝트는 아니었고 동서발전, KTX 한국전력거래소에서 경진대회를 각각 열었다.
동서발전에서는 태양광 발전량을 예측하는 분야로 최우수상을 받았다. 날씨가 좋을 때는 발전량을 예측하기가 쉽지만 흐린 날에는 정확도가 50% 이하로 떨어진다.
그래서 흐린 날 어떻게 예측 정확도를 높일 수 있는지에 대한 창의적인 아이디어였다. 마이크로 날씨 데이터, 위성사진을 추가적으로 분석해서 정확도를 높이는 데 마키나락스의 기술을 적용했다. 이 부분에서 한국전력거래소에서 장려상을 받았다.
저작권자 © 파랑새, 무단전재 및 재배포 금지